Comprehensive Guide to IT Redundancy and Why It is Essential
Most businesses today have become critically dependent on IT systems and their availability.
Without systems to provide redundancy and backups, IT downtime could prove very expensive. Large organizations can be looking at costs of up to $1-5 million per hour in the event of system-wide outages. This doesn't include potential penalties or legal fees in case of data breach or otherwise.
As an operational minimum, every organization needs to have basic redundancies and backups in-place. These can help ensure an organization can keep running regardless of how long it takes to fix the original problem that caused the downtime.
In this guide, we cover IT redundancy in more detail, including the benefits, types of redundancy, and 14 ways to implement an IT redundancy strategy.

What Is IT Redundancy?
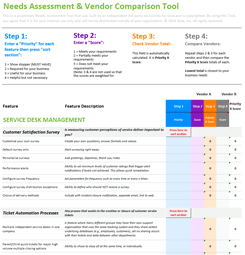
IT redundancy is the duplication of critical IT components and infrastructure so in the event of a failure within an organization's IT infrastructure the backup infrastructure/component can take over.
Without these, in the event of systems failing, there's no way for IT teams to get everything operational until the relevant components are fixed. With backups and IT redundancies, your teams can get back to work quickly, even in the event of a critical outage.
Benefits of IT Redundancy
Now, let's review the benefits of having an IT redundancy strategy. Similar to an insurance policy, even if you never need it — which is rare in IT and ITSM — it's better to have an IT redundancy strategy than not have one.
-
Enhanced Reliability
IT systems are more reliable when there's redundancy built-in, so that they can kick-in whenever it's required. For example, say an email server goes down. It's cloud-based and provided by a third-party.
Suddenly, this means the organization is without email so workplace and client or customer-facing communications (and in many cases, work itself) grinds to a halt. Because it's cloud-based and reliant on the vendor, ITSM teams need to work with them to get it up-and-running again.
What if everything was backed-up on a company-owned and operated server in real-time? This way, email would keep working while the vendor worked hard to restore normal service.
-
Improved Fault Tolerance
Carrying on from the above; when a system doesn't have redundancies then the fault tolerances are zero. For most organizations, this means you're relying on vendor fault tolerances and backups. These are not always reliable either, even if every single vendor operates from Amazon Web Services cloud systems.
Having redundancies improves your system's overall ability to cope with faults and risks, such as cyberattacks and data breaches. Redundancies can help networks and systems cope when there is increased demand and more pressure on IT systems, servers, storage, hardware, and networks.
-
Minimization of Downtime
As noted above and in the following, downtime can be expensive. When Meta, owner of Facebook, WhatsApp, and Instagram suffered downtime in 2021, it knocked 4.9% off the share price and CEO Mark Zuckerberg's personal wealth fell by $6bn.
Of course, for most organizations, downtime doesn't cost billions. However, you should be able to roughly estimate the cost of downtime based on the following:
Your company's annual turnover / 365 / 24 hours = hourly cost of downtime
Plus, you also risk penalties and legal fees (for example, if a data breach or cyberattack has caused downtime).
Having backups and redundancies can help mitigate all of this.
-
Increased System Performance
IT systems can be put under strain for numerous reasons. Sometimes it's simply because of the number of customers accessing services, contacting support, or sales leads wanting to become customers.
In other cases, it's because IT systems are under attack (e.g., a Distributed Denial of Service (DDoS), malware, spyware, ransomware, etc.). Or bad weather is affecting a network or third-party software.
In any scenario, you need a system that can cope with heavier loads and when parts of the IT system are struggling. Having redundancies gives IT leaders the confidence that their systems, hardware, data storage, and network will cope and continue to perform in any scenario.
-
Mitigation of Data Loss Risks
Data losses and data breaches are a serious concern for businesses and organizations of every size. According to the latest IBM Ponemon Institute 2023 Cost of Data Breach Study, the average cost of a data breach to a mid-size or enterprise organization is $4.45 million. This can involve regulatory fines and a significant loss of current and future revenue because customers move elsewhere.
Data loss also includes the inability to access all of the data on the servers they're using. This can be furthered by data corruption. Hence the importance of the amount of uptime cloud providers promise. When a cloud data storage provider promises a certain amount of uptime in Service Level Agreements (SLAs), it means you should have complete access to the cloud services and data storage they're providing for.
Types of Redundancy in IT Systems
There are numerous types of redundancy in IT systems which we will cover in more detail in this section:
-
Hardware Redundancy: Backup hardware systems, cloud-based, in the event of on-site hardware failure
Hardware redundancy means ensuring that every critical piece of hardware, such as processor units, have backup units in the event of a component failure. In most cases, this isn't a standard practice.
If computers break, then an ITSM hardware specialist needs to either fix it, send it to the manufacturer to be fixed, or purchase a new one.
However, for organizations wanting to take backups and redundancies seriously, having spare components of hardware that can take over in the event of a failure reduces the risk of unexpected downtime.
For example, say a server goes down. Without a backup that has everything duplicated onto that server, the contents of it cannot be accessed until the servers are fixed. With a redundant/spare server (that is being used to duplicate everything on the operational server in real-time) it will kick-in as a backup in the event of the main server(s) failing.
Best practices would have the redundant systems always off-site/cloud-based. Also, having multiple vendors can add another layer of backup security.
-
Software Redundancy: Software reboots and cloud-based software backups of critical systems
Most organizations would be lost, or at least struggle to operate, without an extensive tech stack.
In most cases, this tech stack is increasingly cloud-based and provided by Software as a Service (SaaS) vendors. Most SaaS vendors promise 99.999% or more uptime and host their services in popular cloud providers, such as Amazon (AWS), Google, Microsoft, and others. SaaS vendors are also increasingly reliant on OpenAI's products, so those features are also cloud-hosted.
But what happens in the event of a cloud-based failure? What happens to the data you'll need access to if a SaaS provider stops working (e.g., because of an outage)?
SaaS companies will do everything they can to maintain the promised SLA they have with customers. However, SaaS providers should also have their own backups and redundancies. Make sure to ask about this when assessing SaaS providers.
Further, for added peace of mind, ITSM teams can have backups of cloud software and the data they're accessing in redundancy folders. That way, in the event of a failure at the source, the backup version can keep working until the SaaS provider gets operational again. A brilliant way to avoid a loss in productivity.
-
Network Redundancy: A backup network, in the event of network system failure
Network failure is another serious concern of organizations and companies everywhere that rely on the Internet and Wi-Fi for connectivity.
Now, with the rise of cyberattacks and data breaches, more providers offer backup network systems. This can include networks, Wi-Fi, and hard-wired connectivity solutions.
In most cases, these backup networks are entirely cloud-based, so they're set up as virtual private networks. These can be deployed in the event of a network failure or the need to implement an IT business continuity plan.
-
Data Redundancy: Backup data systems, cloud-based storage
Having 24/7 access to data, especially customer data (for customers and customer-facing teams) is essential. If customers can't access their data, it will be immediately seen as a sign that something is wrong. This could cause reputational damage and customers to leave (churn).
Likewise, if customer-facing teams, such as call center agents, customer service, and customer success agents can't access data, then it can cause serious operational issues. Anything that prevents access to the data staff needs for a company to function can lead to major consequences.
Plus, there's always a risk that a cyberattack or data breach could destroy the data an organization has. So, having backup data systems performs two functions:
- Provides a backup in the event of an interruption to the normal databases and other data-based systems
- Provides a backup of the data stored within an organization's systems
Having both will ensure a company operates without worry. If databases collapse there will be immediate access to the same files and systems without any loss of service or data. Your team should be able to carry on as normal with redundancies. These will provide a smooth transition from one system to the next until normal service resumes.
-
Power redundancy: Backup power systems
Almost universally, cloud storage centers should have backup power supplies. Generators are an essential hardware investment for any company that stores data on behalf of clients. So, make sure every data storage center has backup power generators, fire suppression, and security systems.
Next, make sure every site your business operates from has the same or could have the same installed. It could be a sensible investment if you have on-site data storage that either acts as a backup for cloud-based storage, or the on-site storage is the first and most important location for operational and customer data. If that's the case, then having backup power systems could be a mission-critical necessity that you're overlooking and need to invest in.
14 Ways to Implement IT Redundancy
Implementing an IT redundancy strategy can involve multiple approaches to cover as much or as little redundancy as your organization needs. In this section, we cover 14 ways to implement redundancy across the following operational IT functions:
Hardware Redundancy Strategies
Here are three hardware IT redundancy strategies and practical approaches.
-
RAID (Redundant Array of Independent Disks)
One hardware redundancy strategy is known as the Redundant Array of Independent Disks (RAID), and there are numerous ways organizations can implement this.
According to Gartner, RAID is "A method of mirroring or striping data on clusters of low-end disk drives; data is copied onto multiple drives for faster throughput, error correction, fault tolerance and improved mean time between failures."
There are numerous ways of implementing RAID, such as:
- Disk striping without parity information
- Disk mirroring (also called Shadowing)
- Data pattern written across multiple disks using a powerful error detection and correction code (Hamming)
- Disk Mirroring, and several others, usually labeled RAID-0 up to RAID-10
-
Hot standby systems
Hot standby "is a method for making sure that your essential business systems continue to work, uninterrupted, when one or more of its hardware components fail."
Similar to RAID, it makes sure that there are hardware systems and drives that would activate automatically in the event of a primary driver or server failing. In order for hot standby to work, two identical systems (e.g., hard drives or servers) need to work in parallel. Then, the backup (or hot standby system) activates automatically in the event of a primary failure to prevent system downtime. These can be locally or even across multiple data centers.
-
Network and software clustering
Clustering is something organizations can do either for hardware or software. In either scenario, one or more computers or cloud-based storage devices are running in parallel.
Unlike the methods mentioned above, each one is a node in a network, so that if one fails the others can keep going. This is because the data running through the system is distributed across the network rather than on stand-alone devices.
Network and software clustering is another effective way of providing much-needed backups and redundancies within a complex IT network design.
Software Redundancy Strategies
Here are three software IT redundancy strategies and practical approaches.
-
Failover systems
Failover systems are backup software systems that activate by "switching to a computer, system, network, or hardware component that is on standby if the initial system or component fails. It is a state under which the system operates and is achieved when a redundant component kicks in or the system moves into a standby operational mode. Failover is designed to cut down on or completely eliminate the impact on users in the event of a failure."
When failover systems work properly the end-user shouldn't notice any difference. Everything should continue as normal while IT engineers work in the background to get the primary system up and running again.
-
Load balancing
Load balancing is another way of either coping with high-volumes of traffic or having backups ready in the event of a server or other network component failing.
According to the cloud giant, Amazon Web Services (AWS), "Load balancing is the method of distributing network traffic equally across a pool of resources that support an application. Modern applications must process millions of users simultaneously and return the correct text, videos, images, and other data to each user in a fast and reliable manner. To handle such high volumes of traffic, most applications have many resource servers with duplicate data between them. A load balancer is a device that sits between the user and the server group and acts as an invisible facilitator, ensuring that all resource servers are used equally."
-
Virtualization of software and other critical systems
Virtualization of software is another way to protect against critical system, storage, or hardware failures (as you can even mirror hardware using cloud-based virtualization).
According to Amazon Web Services (AWS): "Virtualization is technology that you can use to create virtual representations of servers, storage, networks, and other physical machines. Virtual software mimics the functions of physical hardware to run multiple virtual machines simultaneously on a single physical machine.
Network Redundancy Strategies
Here are three network IT redundancy strategies and practical approaches.
-
Redundant network paths
Network redundancy is another way to safeguard an organization from unexpected network component failures. Think of your networks as a series of interconnected freeways or railway lines. If one fails, it's not a major problem because traffic can be automatically re-routed along other paths to absorb the same amount of traffic.
-
Dual-homed connections
In most cases, hardwired computers only have one connection to the Internet. With dual-homed connections, there are two or more, so that in the event one fails the other(s) can automatically take over. This way, a computer or other device doesn't lose network connectivity.
IT teams can even ensure that the other connection is provided by a backup Internet provider. If one has unexpected downtime, the other will still be operational.
-
Network Load Balancing (NLB)
Network Load Balancing (NLB) is another way to de-risk networks with backups. It's more common for organizations with Microsoft networks and systems, particularly Windows Server 2022, Windows Server 2019, and Windows Server 2016.
Also, since 2016, organizations with Microsoft networks and systems can benefit from an Azure-inspired Software Load Balancer (SLB) as a component of the Software Defined Networking (SDN) infrastructure.
According to Microsoft, NLB "distributes traffic across several servers by using the TCP/IP networking protocol. By combining two or more computers that are running applications into a single virtual cluster, NLB provides reliability and performance for web servers and other mission-critical servers."
Data Redundancy Strategies
Here are three data IT redundancy strategies and practical approaches.
-
Backup and recovery solutions
Data backup and recovery solutions are the minimum that any ITSM team and cloud providers should be offering. Having data backups is essential for any organization to protect against downtime, data breaches, and human error.
Data backup and recovery "is the process of duplicating data and storing it in a secure place in case of loss or damage, and then restoring that data to a location — the original one or a safe alternative — so it can be again used in operations. Ideally, this backup copy (often called a snapshot) is immutable —meaning it cannot be altered after it is created to protect against mutations such as ransomware. Backup and recovery is also a category of onsite and cloud-based technology solutions that automate and support this process, enabling organizations to protect and retain their data for business and compliance reasons."
-
Replication
Replication is another feature of backup and recovery processes. This is where data on one or more servers is replicated to others, and these replications are either happening in real-time, incrementally, or at least every 24-hours. How often data is replicated depends on how high-value the data is and how much data is produced, altered, or processed every 24 hours (or 1 working day).
When an organization is handling large volumes of data, it is important for it to be replicated and stored securely on separate systems, away from where it's produced and processed. If you are storing backup data on the same servers as your primary systems, then if anything goes wrong, you risk losing everything.
-
Disaster recovery planning
Disaster recovery planning is one of the main reasons that ITSM teams and CIOs invest in backup and recovery solutions. Having a disaster recovery plan ensures that an organization is prepared for the worst. Examples could be a critical IT failure or another avoidable disaster.
Disaster recovery planning should include everything outlined in this article, such as data, network, software, power supply, and hardware backup and recovery systems. So, in the event of a serious outage, cyberattack, or company-wide or site-specific disaster (e.g., fire, flood, terrorist attack, etc.), the company can keep working and stay operational.
Power Redundancy Strategies
Here are two power redundancy strategies and practical approaches.
-
Uninterruptible Power Supply (UPS)
An Uninterruptible Power Supply (UPS) is a backup power supply that isn't reliant on the national grid, or any national or local energy supplies. For example, server farms and hospitals, and other critical infrastructure sites often have backup generators that automatically take over if main power is interrupted. This way, the organization still has the power to keep critical systems functioning.
-
Redundant power supplies
Similar to the above, but less seamless, having a redundant power supply de-risks a mission-critical system failure. If the power goes down, backup power can be brought online so networks and hardware can keep working.
Challenges and Considerations When Implementing Redundancy and Backups in IT
There are numerous challenges and considerations when it comes to implementing redundancy and backups in IT. Here is what most organizations have to overcome when implementing them.
-
Cost Implications of Implementing Redundancy Measures
Having IT redundancies and backups costs money. That's why it's not something every organization can afford to maintain.
Some of the most cost-effective implementations are with third-party ITSM, SaaS, cloud-storage, and business continuity providers. Find out how to make it affordable before building a business case for having IT redundancy measures and backups.
-
Complexity in Managing Redundant Systems
Complexity is another reason why IT leaders and CIOs are hesitant, at times, to operate and manage redundant and backup systems. Questions arise, such as, how do we maintain these backup systems? Can we automate this?
Thankfully, automation can be built into backup system provisions. The systems should be self-maintaining so that they are not something that IT engineers need to consistently worry about alongside the "live" and active systems that are in use on a daily basis.
-
Ensuring Compatibility and Interoperability
Compatibility and interoperability should be front-loaded and built into any IT redundancies. Everything you have that operates in a backup capacity needs to function with every other system you have that powers your organization. Design this as a default to avoid problems later, especially when you need your backup systems the most.
-
Monitoring and Testing Redundancy Setups
The worst time to test a parachute is when you've already jumped out of a plane.
Make sure to test and validate redundant systems automatically, every 30 days as a minimum. Ensure automatic monitoring systems are running for backup software, hardware, and networks.
-
Balancing Redundancy with Resource Utilization
Having redundancies is important. However, C-suite leadership might be hesitant to support this IT insurance policy if it absorbs too many resources. Human time to set up, monitor, and maintain costs money, so it's important to ensure resource utilization is kept to a minimum.
The more that can be automated and outsourced around the setup, monitoring, and management of these resources, the better. Make sure that redundancies are cost-effective, don't absorb a lot of human or financial resources, and don't require a lot of looking after.
Future Trends in IT Redundancy
And finally, here are a few future trends to think about in IT redundancy.
-
Automation and Self-Healing Systems
Imagine a world where an IT system can be hit by a cyberattack, fights back, recovers the data, and heals itself? This is like an immune system, except it consists of self-healing, AI-based IT systems.
It's certainly possible, with technologies such as AI and with supercomputers, making it potentially a not-too-distant reality. We could have IT systems that automatically take care of backups and recover from faults, errors, and even cyberattacks.
-
Integration of AI and Machine Learning for Predictive Redundancy
Predictive redundancy is the next step and evolution of backups and redundant IT systems and networks. Thanks to advances in AI and machine learning, numerous IT software providers already include AI-based systems in their offerings. It might not be long until we have SaaS-based redundancy and backup systems that can predict when they need to go online in the event of a primary system failing.
-
Advances in Cloud-Based Redundancy Solutions
As David Linthicum, of Deloitte Consulting, said in TechTarget, the best way to safeguard against cloud computing, even backup failure, is to: "Consider a multi-cloud model to ensure redundancy and backup."
He continues: "Organizations place their primary systems on one cloud platform, such as AWS, and their backup or secondary systems on another cloud platform, such as Microsoft Azure. IT teams then continuously update those redundant systems with the same data on both cloud instances. If the primary provider experiences an outage, workloads can continue to run with the backup cloud provider."
-
Incorporating Redundancy in Edge Computing
As IT and consulting giant, Accenture, says, edge computing, "is an emerging computing paradigm which refers to a range of networks and devices at or near the user. Edge is about processing data closer to where it's being generated, enabling processing at greater speeds and volumes, leading to greater action-led results in real-time."
As edge computing becomes more of a normal part of software, hardware, and other operational IT systems, it's important to ensure that redundancies there aren't overlooked.
Key Takeaways: The Essential Need of Redundancy in IT
IT redundancy is the process of ensuring there are systems, processes, procedures, hardware, software, networks, and power supplies in place to get up and running in the event of an IT failure, including cyberattacks and data breaches.
Failing to plan is planning to fail. IT systems availability is now more than ever imperative for the success and life of most every business. Review the strategies for your IT redundancy plans today to avoid business loss and even potentially a damaged reputation.
Ready to Experience the Giva Difference?
Learn about Giva's intuitive and robust IT Help Desk and ITSM software in the cloud:
- You'll be up and running in days, and your IT Service Management team can be trained in hours on our intuitive and friendly interface. Giva provides video tutorials, self paced tours, quick start guides and FAQs.
- Internet connections make everything vulnerable to cyberattacks, data breaches, malware, etc. We use strong encryption and HIPAA-compliant hardened and secure infrastructure to protect your PHI and other private data. Giva also has a SSAE 18 SCO II Type 2 certification, and we support native Multi-factor Authentication (MFA).
- Giva follows the latest industry-leading ITIL® best practices including ITIL v4. ITIL is a best-practice framework or set of best practices that guide ITSM.
- Our reports and dashboards are not only visually appealing, but they're easy to understand. Giva has the best real-time custom reporting and KPIs: Full color charts and graphs. You can create, save, share and schedule delivery of standard and custom reports.
Your support help desk team will need very little training with Giva's intuitive platform. Try Giva today!



Categories: Technology, IT